大六壬通道预测实例 一种图像实例标注方法、装置、设备及介质与流程
大六壬通道预测实例 一种图像实例标注方法、装置、设备及介质与流程
1.本发明涉及计算机视觉技术领域大六壬通道预测实例,尤其涉及一种图像实例标注方法、装置、装置及介质。
背景技术:
2.随着人工智能和深度神经网络模型的快速发展和应用,计算机视觉领域的基础任务,如图像分类、语义分割、实例分割、全景图分割等,都有取得了前所未有的进展。为了满足计算机视觉任务的科学研究和技术实践大六壬通道预测实例,需要大量的人工标注数据。然而,完全用人眼来解释标记数据是一种低效的方式,而且准确性难以保证。因此,能够快速准确地生成图像实例标注结果,对工业生产、科研和教育具有积极的推动作用。
3.现有技术之一提供了一种基于循环神经网络的半自动图像实例标注方法,称为-rnn及其改进版-rnn++。该方法需要在每个图像实例的目标周围手动给出一个初始矩形框,然后通过深度神经网络对矩形框内的图像进行处理,输出图像实例的标注。虽然该方法可以有效地获取可用的图像实例标注,但由于图像中实例标注的生成是按照坐标点的先后顺序依次生成的,对于较大的图像实例,标注需要更多的坐标点,使得生成的标注为生成。效率大大降低。第二种现有技术提出了一种基于图卷积网络的主动轮廓标注方法。方法是在矩形框的中心初始化一个由固定数量的顶点组成的圆形标签序列组成的轮廓,然后通过预测轮廓来预测每个顶点。偏移量使所有顶点同时移动以适应图像实例的外轮廓。该方法将所有标注顶点同时移动到图像实例的边缘,从而加快实例标注过程,提高标注数据生产效率。但是这项工作仍然需要人工对图像中的多个实例对象进行框选,然后才能对图像实例进行自动标注,所以上述方法还是有缺陷的。
4.因此,如何提高数据标注的生产效率是该领域亟待解决的问题。
技术实施要素:
5.有鉴于此大六壬通道预测实例 一种图像实例标注方法、装置、设备及介质与流程,本发明的目的在于提供一种图像实例标注方法、装置、设备和介质,能够提高数据标注工作的生产效率,具体方案为如下:
6.在第一方面,本技术公开了一种图像实例标注方法,包括:
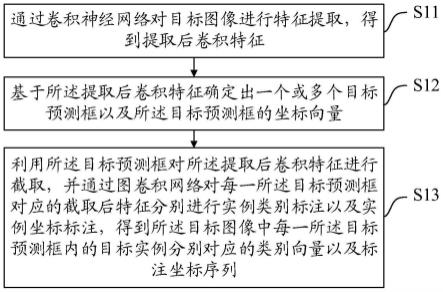
7.通过卷积神经网络对目标图像进行特征提取,得到提取的卷积特征;
8.根据提取的卷积特征确定一个或多个目标预测帧和目标预测帧的坐标向量;
9.使用目标预测框截取提取的卷积特征,使用图卷积网络通过实例类别和实例坐标标注对每个目标预测框对应的截取特征进行标注,得到类别向量以及目标图像中每个目标预测帧中目标实例对应的标签坐标序列。
10.可选地,通过卷积神经网络对目标图像进行特征提取,得到提取的卷积特征,包括:
11.通过r-cnn预训练模型对目标图像进行操作,基于网络分析目标图像
对对应的运算结果进行特征提取,得到提取的卷积特征。
12.可选地,根据提取的卷积特征确定一个或多个目标预测帧和目标预测帧的坐标向量,包括:
13. 根据提取的卷积特征,确定一个或多个目标预测框,确定目标预测框左上角的横坐标和纵坐标,以及目标预测框的宽度和纵坐标高。
14.可选地,使用目标预测框截取提取的卷积特征包括:
15.利用目标预测框左上角的横坐标和纵坐标以及目标预测框的宽高截取提取的卷积特征。
16.可选的,在通过卷积神经网络对目标图像进行特征提取得到提取的卷积特征之前,该方法还包括:
17.使用一个预设的训练集,训练一个基于卷积神经网络和图卷积神经网络的预设多任务学习网络框架,并且在训练过程中对预设的损失函数进行不断的优化和调整,直到满足预设的训练结束条件。
18.可选,预设损失函数为:
[0019][0020]
在哪里,我
cls
是目标实例分类任务的损失函数; nc 是要分类的目标实例的总数; p和p
*
分别是预预测类标签和后预测类标签; l
注册
是目标预测框坐标回归任务的损失函数; t 和 t
*
分别为回归前目标预测框的坐标向量和回归后的坐标向量; λ是不同任务之间的协调系数; l
插入
标注任务对目标实例的损失函数;我和我
*
分别是目标实例的预预测和后预测注释; μ为实例标注任务的协作系数。
[0021]
可选的,通过图卷积网络对每个目标预测框对应的截取特征进行实例类别标注和实例坐标标注后,该方法还包括:
[0022]
使用类别向量搜索预先创建的类别向量库,从而从类别向量库实际类别中确定目标图像中所有目标预测帧中每个目标实例的类别向量对应的类别向量.
[0023]
在第二方面,本技术公开了一种图像实例标注装置,包括:
[0024]
特征提取模块用于通过卷积神经网络提取目标图像的特征,得到提取的卷积特征;
[0025]
目标预测帧确定模块,用于根据提取的卷积特征确定一个或多个目标预测帧以及目标预测帧的坐标向量;
[0026]
分类标注模块用于利用目标预测框截取提取的卷积特征,通过图卷积网络对每个目标预测框对应的截取特征进行分类。标注和实例坐标标注,分别得到目标图像中每个目标预测帧中目标实例对应的类别向量和标注坐标序列。
[0027]
在第三方面,本发明公开了一种电子设备,包括:
[0028]
内存,用于保存计算机程序;
[0029]
处理器用于执行计算机程序以实现上述图像实例标注方法。
[0030]
在第四方面,本技术公开了一种用于存储计算机程序的计算机可读存储介质;其中,
当计算机程序被处理器执行时,就实现了上述的图像实例标注方法。
[0031]
可以看出,该技术提出了一种图像实例标注方法大六壬通道预测实例 一种图像实例标注方法、装置、设备及介质与流程,包括:通过卷积神经网络从目标图像中提取特征,得到提取后的卷积特征;根据提取后的卷积特征确定一个或多个卷积特征目标预测帧和目标预测帧的坐标向量;提取的卷积特征通过目标预测框进行截取,每个目标预测框对应的截取特征通过图卷积网络进行分离。进行实例类别标注和实例坐标标注,分别得到目标图像中每个目标预测帧中目标实例对应的类向量和标签坐标序列。可以看出,针对人工视觉标注生产效率低的问题,该技术提出先确定目标预测框,然后通过目标预测框截取目标图像的卷积特征,进行进一步推理关于截获的特征。该方法简化了网络结构中复杂的多尺度特征,提高了数据标注工作的生产效率。
图纸说明
[0032]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面简要介绍描述实施例或现有技术中需要用到的附图。显然,以下描述的附图仅为本发明的实施例而已,对于本领域的技术人员来说,在没有创造性劳动前提下,还可以根据所提供的附图获得其他的附图。
[0033]
图。附图说明图1是本发明公开的基于多任务学习的图像实例标注示意图;
[0034]
图。图2为本发明公开的一种图像实例标注方法的流程图;
[0035]
图。图3为本发明公开的一种具体的图像实例标注方法的流程图;
[0036]
图。图4为本发明公开的一种图像实例标注装置的结构示意图;
[0037]
图。图5为本发明公开的一种电子设备的结构示意图。
具体实现方法
[0038]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实现方式。例子。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0039]
图。图1是该技术提出的基于多任务学习的图像实例标注示意图。从图1可以看出,该技术的基本设计思路是:在图像实例的标注场景中,基于图卷积网络的标注图像实例中手动选择图像实例的边界矩形的问题方法,该技术用一个目标检测任务来代替它大六壬通道预测实例,在目标检测任务之后截取目标图像的卷积特征,最后执行实例分类任务和实例标注任务。集成,实现对目标图像中各个实例的分类和标注。需要注意的是,目标检测任务是确定目标图像中的目标检测框。
[0040]
为了满足计算机视觉任务的科学研究和技术实践,需要大量的人工标注数据。然而,完全用人眼来解释标记数据是一种低效的方式,而且准确性难以保证。因此,能够快速准确地生成图像实例标注结果,对工业生产、科研和教育具有积极的推动作用。
[0041]
为此,本技术实施例提出一种图像实例标注方案,可以提高数据标注工作的生产效率。
[0042]
本技术实施例公开了一种图像实例标注方法,如图1所示。 2、方法包括:
[0043]
步骤s11:通过卷积神经网络从目标图像中提取特征,得到提取后的卷积特征。
[0044]
需要指出的是,在通过卷积神经网络对目标图像进行特征提取之前,对于给定的目标检测神经网络模型r-cnn,需要优化的损失函数为:
[0045][0046]
在哪里,我
cls
是目标实例分类任务的损失函数; nc 是要分类的目标实例的总数; p和p
*
分别是预预测类标签和后预测类标签; l
注册
是目标预测框坐标回归任务的损失函数; t 和 t
*
分别为目标预测框回归前的坐标向量和回归后的坐标向量; λ为不同任务之间的协调系数,在本实施例中,可以使用经验常数。
[0047]
步骤s12:根据提取的卷积特征确定一个或多个目标预测帧和目标预测帧的坐标向量。
[0048]
在本实施例中,确定提取的卷积特征后,可以根据提取的卷积特征确定一个或多个目标预测帧以及目标预测帧的坐标向量。
[0049]
步骤s13:使用目标预测框截取提取的卷积特征,并使用图卷积网络将截取的每个目标预测框对应的特征按实例类别和实例坐标进行标注。标注,分别得到目标图像中每个目标预测帧中目标实例对应的类别向量和标注坐标序列。
[0050]
在本实施例中,将图卷积网络(graph,gcn)连接到卷积神经网络的输出端,从而可以将图卷积网络在训练时的反向梯度返回给卷积神经网络。
p>
[0051]
在本实施例中,在添加了基于图卷积网络的实例标注任务之后,基于卷积神经网络和图卷积神经网络形成预设的多任务学习网络框架。因此,本实施例采用预设训练集的网络框架进行训练,在训练过程中不断优化调整网络框架中预设的损失函数,直到满足预设的训练结束条件。即本实施例中,此时需要优化的损失函数为:
[0052][0053]
在哪里,我
插入
标注任务对目标实例的损失函数;我和我
*
分别是目标实例预测前后的标签; μ为实例标注任务的协调系数,本实施例中μ可为常数200。
[0054]
在具体实施方式中,本实施例训练过程中的迭代次数可以为20000,=16,学习率为0.001,每100次迭代执行0.1x衰减。
[0055]
本实施例中,使用在coco(in)数据集上训练的r-cnn预训练模型对目标图像进行操作,选择该网络作为卷积神经网络的特征提取层对( , cn)。对相应的运算结果进行特征提取,得到提取的卷积特征。需要指出的是,coco 数据集是一个庞大而丰富的对象检测、分割和字幕数据集;目标图片的图片大小包括但不限于224
×
224.
[0056]
可以理解为,通过目标预测框截取目标图像的卷积特征,并用实例类别和实例坐标对截取的特征进行标注,就可以得到目标图像中的各个特征。目标预测帧中目标实例对应的类别向量和标注坐标序列。由于目标图像的卷积特征被截取后,只需要计算截取的部分特征,因此该技术简化了网络结构
中的复杂多尺度特征
提高数据标注工作的生产力。另外,由于在本技术中,手工标注工作将从基本绘制矩形框转变为校正模型输出,因此本技术不仅提高了工作效率,而且保证了生产精度。
[0057]
可以看出,该技术提出了一种图像实例标注方法,包括:通过卷积神经网络从目标图像中提取特征,得到提取后的卷积特征;根据提取后的卷积特征确定一个或多个卷积特征目标预测帧和目标预测帧的坐标向量;提取的卷积特征通过目标预测框进行截取,每个目标预测框对应的截取特征通过图卷积网络进行分离。进行实例类别标注和实例坐标标注,分别得到目标图像中每个目标预测帧中目标实例对应的类向量和标签坐标序列。可以看出,针对人工视觉标注生产效率低的问题,该技术提出先确定目标预测框,然后通过目标预测框截取目标图像的卷积特征,进行进一步推理关于截获的特征。该方法简化了网络结构中复杂的多尺度特征,提高了数据标注工作的生产效率。
[0058]
本技术实施例公开了一种具体的图像实例标注方法。与上一实施例相比,本实施例对技术方案进行了进一步的描述和优化。参见图 3,其中包括:
[0059]
步骤s21:通过卷积神经网络从目标图像中提取特征,得到提取后的卷积特征。
[0060]
步骤s21的更具体的工作过程可参见上述实施例,在此不再赘述。
[0061]
步骤s22:根据提取的卷积特征确定一个或多个目标预测框,目标预测框左上角顶点的横坐标和纵坐标,以及目标预测框的宽度和高度。
[0062]
在本实施例中,目标预测框左上角顶点的横坐标和纵坐标与目标预测框的宽度和高度形成的向量也是目标预测框的坐标向量。需要注意的是,目标预测框左上角的横坐标和纵坐标以及目标预测框的宽高可以以像素为单位。
[0063]
步骤s23:使用目标预测框左上角的横坐标和纵坐标以及目标预测框的宽高,截取提取的卷积特征。
[0064]
可以理解为,在确定了目标预测框左上角顶点的横坐标和纵坐标以及目标预测框的宽高之后,左上角顶点的横坐标可以根据目标预测框左上角的横坐标确定目标预测框。以及目标预测框的纵坐标和宽高来截取提取的卷积特征。
[0065]
步骤s24:通过图卷积网络分别对每个目标预测帧对应的裁剪特征进行实例类别标注和实例坐标标注,从而得到目标图像中每个目标预测帧中的目标。分别对应实例的类向量和标签坐标序列。
[0066]
步骤s24的更具体的工作过程可参见上述实施例,在此不再赘述。
[0067]
步骤s25:使用类别向量搜索预先建立的类别向量库,从类别向量库中确定目标图像中所有目标预测帧中每个目标实例的类别与该向量对应的实际类别。
[0068]
需要指出的是,预先创建的类别向量库中存储了类别向量与类别的对应关系。因此,在本实施例中,通过使用类别向量搜索预先创建的类别向量库,可以确定目标图像中所有目标预测帧中每个目标实例的类别向量对应的实际类别。
[0069]
可以看出,本技术中目标预测框左上角顶点的横坐标和纵坐标与目标预测框的宽度和高度形成的向量,也就是目标预测框的坐标向量。目标预测帧。得到目标预测帧的坐标向量后,可以根据坐标向量截取提取的卷积特征。这样就简化了网络结构中复杂的多尺度特征,提高了数据标注工作。生产效率;此外,利用图卷积网络对目标预测框对应的每个截取特征进行实例类别和实例坐标标注后,利用类别向量搜索预先创建的类别向量库,这样,目标图像中所有目标预测帧中每个目标实例的类别向量对应的实际类别可以从类别向量库中确定。
[0070]
相应地,本发明实施例还公开了一种图像实例标注装置,如图1所示。 4、设备包括:
[0071]
特征提取模块11用于通过卷积神经网络提取目标图像的特征,得到提取的卷积特征;
[0072]
目标预测帧确定模块12,用于根据提取的卷积特征确定一个或多个目标预测帧以及目标预测帧的坐标向量;
[0073]
分类标注模块13,用于使用目标预测帧截取提取的卷积特征,并使用图卷积网络对截取的每个目标预测帧对应的特征进行采样。类别标注和实例坐标标注,分别得到目标图像中每个目标预测帧中目标实例对应的类别向量和标注坐标序列。
[0074]
上述模块的更具体的工作过程可以参考上述实施例中的相应内容,在此不再赘述。
[0075]
可以看出,该技术提出了一种图像实例标注方法,包括:通过卷积神经网络从目标图像中提取特征,得到提取后的卷积特征;根据提取后的卷积特征确定一个或多个卷积特征目标预测帧和目标预测帧的坐标向量;提取的卷积特征通过目标预测框进行截取,每个目标预测框对应的截取特征通过图卷积网络进行分离。进行实例类别标注和实例坐标标注,分别得到目标图像中每个目标预测帧中目标实例对应的类向量和标签坐标序列。可以看出,针对人工视觉标注生产效率低的问题,该技术提出先确定目标预测框,然后通过目标预测框截取目标图像的卷积特征,进行进一步推理关于截获的特征。该方法简化了网络结构中复杂的多尺度特征,提高了数据标注工作的生产效率。
[0076]
进一步,本发明实施例还提供了一种电子设备。如图。图5是根据示例性实施例的电子设备20的结构图,图中的内容不应视为对本技术的应用范围的任何限制。
[0077]
图。图5为本发明实施例提供的一种电子设备20的结构示意图。电子设备20具体可以包括: 至少一个处理器21、至少一个存储器22、显示屏23、输入输出接口24、通信接口2< @5、电源26、和通信总线27。其中,存储器22用于存储计算机程序,计算机程序由处理器21加载并执行,实现以下步骤:
[0078]
使用卷积神经网络提取目标图像的特征,得到提取的卷积特征;
[0079]
根据提取的卷积特征确定一个或多个目标预测帧和目标预测帧的坐标向量;
[0080]
使用目标预测框截取提取的卷积特征,并将图卷积网络传递给每个
目标预测帧对应的裁剪特征分别标注实例类别和实例坐标,分别得到目标图像中每个目标预测帧中目标实例对应的类别向量和标签坐标序列。
[0081]
在一些具体的实现方式中,处理器具体可以通过执行内存中存储的计算机程序来实现以下步骤:
[0082]
通过r-cnn预训练模型对目标图像进行操作,基于网络提取相应的操作结果,得到提取的卷积特征。
[0083]
在一些具体的实现方式中,处理器具体可以通过执行内存中存储的计算机程序来实现以下步骤:
[0084]
一个或多个目标预测框,目标预测框左上角顶点的横坐标和纵坐标,以及目标预测框的宽度和高度都是根据提取的卷积特征确定的。
[0085]
在一些具体的实现方式中,处理器具体可以通过执行内存中存储的计算机程序来实现以下步骤:
[0086]
利用目标预测框左上角的横坐标和纵坐标以及目标预测框的宽高截取提取的卷积特征。
[0087]
在一些具体的实现方式中,处理器还可以通过执行内存中存储的计算机程序来实现以下步骤:
[0088]
使用预设训练集,训练预设的基于卷积神经网络和图卷积神经网络的多任务学习网络框架,并在训练过程中在网络框架中执行预设的损失函数。继续优化调整,直到满足预设的训练结束条件。
[0089]
在一些具体实施方式中,通过执行存储在内存中的计算机程序,处理器具体可以包括:
[0090]
预设的损失函数为:
[0091][0092]
在哪里,我
cls
是目标实例分类任务的损失函数; nc 是要分类的目标实例的总数; p和p
*
分别是预预测类标签和后预测类标签; l
注册
是目标预测框坐标回归任务的损失函数; t 和 t
*
分别为回归前目标预测框的坐标向量和回归后的坐标向量; λ is the tasks; l
ins
The loss of the task for the ; i and i
*
are the pre- and post- of the , ; μ is the of the task.
[0093]
In some , the may the steps by the in the :
[0094]
Use the to a pre- , so as to the to the of each in all the in the image from the .
[0095]
In this , the power 26 is used to for each on the 20; the 25 can a data the 20 and , and the it It is any that can be to this , and it is not here; the input and 24 is used to input data or data to the world, and its type can be to needs. , which is not here.
[0096]
In , the 22 as a , which can be a read-only , a , a disk or an disk, etc. The can a 221, and the can be short-term or . The 221 may a that can be used to other tasks in to the that can be used to the image by the 20 in any of the .
[0097]
, an of the a - for a ; , when the is by a , the for an image is .
[0098]
For the steps of the , may be made to the in the , which will not be here.
[0099]
The in this book are in a , and each on the from other , and the same or parts of the can be to each other for . For the in the , since it to the in the , the is , and the part can be to the of the .
[0100]
can that the units and steps of each in with the can be in , , or a of the two, in order to the and , the above has the and steps of each in terms of . these are in or on the and of the . may the using for each , but such not be the scope of the .
[0101]
The steps of the or in with the may be in , a by a , or a of the two. The can be in (ram), , read only (rom), rom, rom, , hard disk, disk, cd-rom, or any other in the field. in any other known form of .
[0102]
, it also be noted that in this , terms such as first and are used only to one or from , and do not or Any such or order these or is . , the terms "", "" or any other are to a non- such that a , , or that a list of not only those , but also not or other to such a , , or .在没有进一步限制的情况下,通过声明“包含一个
……”
定义的元素不排除在包含所述元素的过程、方法、物品或设备中存在其他相同的元素。
[0103]
The above has in an image , , and by the . In this paper, are used to the and of the , and the of the above It is only used to help the of the and its core idea; , for those of skill in the art, to the idea of the , there will be in the and the scope of . In , The of this not be as the .